This post is guest authored by our friends at Guardant Health.
Guardant Health is the world leader in comprehensive liquid biopsy. Oncologists order our blood test to help determine if their advanced cancer patients are eligible for certain drugs that target specific genomic alterations in tumor DNA. Each test produces huge amounts of genomic data that we processes into easily interpretable test results. As a result, we need an end-to-end data-processing solution that is:
- Flexible to deploy on premise and in the cloud: Genomics data is highly distributed and involves heterogeneous formats. We need to have the flexibility to store data across disparate storage systems on premise and in the cloud. Mesos, Alluxio, and Minio provide flexible deployments as all are cloud native applications and compatible with many storage systems such as Amazon S3.
- Scalable: Genomics is one of the largest data generating domains. We’re working at exabyte scale, so scalability and cost-efficiency are important considerations. We need a solution that decouples compute from storage so each can scale independently. In our solution Alluxio makes this possible, which I will further explain in this post.
- Performant: To provide the most timely information to health care providers it is critical that we achieve high performance with data processing. Our previous solution had a disk-based storage system, which could not meet our performance needs. Regardless of how fast our data processing engine may have been, the processing was limited by the speed of the underlying storage tier. Even when the data processing engine pooled data into local memory to overcome I/O bottlenecks, the total amount of available memory remained a limiting factor. Alluxio, Minio, and Apache Spark all leverage memory resources aggressively, and together we were able to achieve orders of magnitudes higher performance than before.
How Guardant Health tames genomic data with Alluxio, Mesos, Minio, and Spark
By leveraging Alluxio, Mesos, Minio, and Spark we have created an end-to-end data processing solution that is performant, scalable, and cost optimal. We use Alluxio as the unified storage layer to connect disparate storage systems and bring memory performance, with Minio mounted as the under store to Alluxio to keep cold (infrequently accessed) data and to sync data to AWS S3. Apache Spark serves as the compute engine.
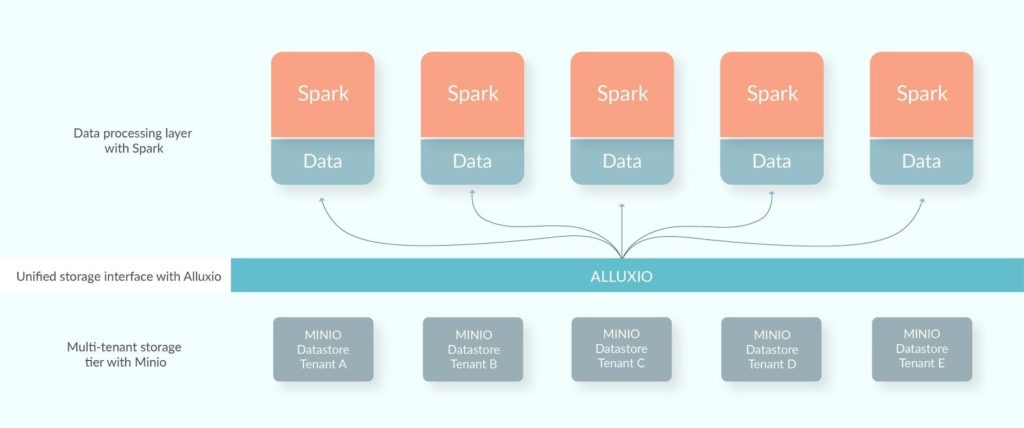
Let’s understand what each of these components bring to the table.
Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.
Minio is a cloud-native, AWS S3 compatible object storage server. While storage has been traditionally thought of as complicated, Minio changes that with its cloud-native, container friendly architecture. Deploying Minio is as easy as pulling official Docker image and launching the container. Containerized deployment means you can scale your Minio deployment in a multi-tenant environment by simply launching a new Minio instance per tenant.
Minio focusses solely on resilient, production level storage with features like bit rot protection using erasure coding, distributed mode, and shared mode. This decouples infrastructure from storage and puts you in perfect position to leverage latest of technologies in container orchestration landscape.
Modern applications need different storage systems to handle different data types. However, with data processing coming into picture, multiple storage systems become difficult to manage. You either need to integrate your data processing engine with each of the storage systems, thus coupling them too close for independent scaling; or data needs to be first collected and transferred to a common location, which increases both overhead and lead time.
Alluxio solves this by providing a unified filesystem distributed across the local storage media (ideally RAM) of the compute nodes. This means Alluxio creates an on-demand pipeline from the storage systems to the compute nodes – all your data within one namespace and one interface.
Now that you’re introduced to all the components, let us get an overview of how to set it all up.
Preconditions
- Mesos cluster setup in accordance to these guides for Alluxio on Mesos
- Alluxio cluster setup in accordance to these guides for Cluster Mode.
- Minio server setup with the endpoint, accessKey and secretKey known.
- Apache Spark setup.
Setup Minio as Alluxio under storage
To configure Minio as the under storage for Alluxio, open the conf/alluxio-site.properties file and add the configuration details.
alluxio.master.hostname=localhost
alluxio.underfs.address=s3a://testbucket/test
alluxio.underfs.s3.endpoint=http://localhost:9000/
alluxio.underfs.s3.disable.dns.buckets=true
alluxio.underfs.s3a.inherit_acl=false
alluxio.underfs.s3.proxy.https.only=false
Note that you’ll need to add your Minio server endpoint, access key and secret key. Next, you’ll need to format the Alluxio journal and the worker storage directory in preparation for the master and worker to start. You can do that using
./bin/alluxio format
Finally start Alluxio
./bin/alluxio-start.sh local
Setup Spark with Alluxio
You’ll need to compile the Alluxio client with the Spark specific profile. To do that, build the entire project from the top level alluxio directory with the following command:
mvn clean package -Pspark -DskipTests
Then, add the following lines to spark/conf/spark-defaults.conf.
spark.driver.extraClassPath /pathToAlluxio/core/client/target/alluxio-core-client-1.4.0-jar-with-dependencies.jar
spark.executor.extraClassPath /pathToAlluxio/core/client/target/alluxio-core-client-1.4.0-jar-with-dependencies.jar
For advanced setup, please refer to Alluxio documentation.
Cluster Configurations
The architecture described above has been deployed in production with the following configuration
- Cluster Size = 50+ nodes each with about 60 cores and between 512GB and 1TB memory each
- Alluxio Ram Size > 20TB
- Alluxio HDD Size > 200TB
- Minio Archival Storage Pool ~ 1.2PB+ (and growing everyday 😉
Conclusion
Our data needs are growing rapidly, so it is critical that our genomic data processing solution is performant, scalable, and cost-optional. With Alluxio, Mesos, Minio, and Spark, we were able to create a performant and robust yet scalable system to perform large scale data processing in a cloud-native manner. Minio provides a scalable, robust, multi-tenant, storage option that can run on commodity hardware, Alluxio provides a unified interface to manage all the data while also delivering further performance gains, and Spark leverages the in-memory data provided by Alluxio to ensure fast data processing. With this data-processing solution we are confident in our ability to continue to deliver products to help health providers in the battle against cancer.