This blog explores the benefits Alluxio brings to data platforms, including:
- The trends behind the rise of decoupled compute-storage architectures
- How Alluxio addresses data access issues for decoupled compute-storage architectures
- An example of Alluxio’s benefits using a SparkSQL workload
Motivation
The primary appeal of a coupled compute-storage architecture, an architecture where the computation is happening on the machines where the data resides, is the performance possible by bringing the compute engine to the data it requires; however, the costs of maintaining such tight-knit architectures are gradually overtaking the performance benefits. Especially with the popularity of cloud resources, being able to independently scale compute and storage results in large cost savings and cheaper maintenance.
In addition, data has become the new oil, and all modern organizations are looking to capture as much data as possible. Deriving value from the data is often several steps away from deciding to store data, so tightly coupling compute and storage is impractical. The reversal of the compute-storage paradigm puts many data platforms in a tough position and forced to trade between performance, cost, and flexibility. Alluxio solves this dilemma by providing the same, if not better, performance of a coupled compute-storage architecture in a flexible, decoupled architecture.
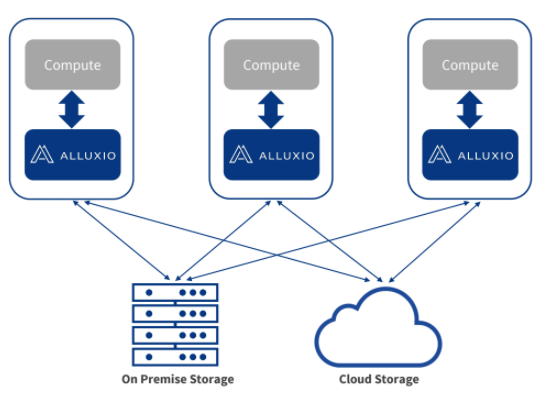
How Alluxio Helps
Alluxio achieves this by providing a near-compute cache when Alluxio is deployed with, or alongside, compute nodes. Applications and compute frameworks send requests through Alluxio, which in turn fetches data from remote storage systems. Along the way, Alluxio maintains a cached copy of the data in Alluxio storage, be it in memory or durable media available on the Alluxio nodes.
Then, future requests are automatically served through the cached copy. This essentially enables coupled compute-storage architecture performance or better. However, Alluxio only deals with the working set and does not hold persistent data. Therefore, Alluxio does not need a significant amount of storage and can function on a limited storage size, regardless of the total data size. Alluxio also utilizes multiple cache and data management techniques to efficiently manage capacity.
Alluxio sits between compute and storage and provides a single point of data access and integration. This means applications can freely use any of the standard APIs supported by Alluxio, such as S3 or Hadoop compatible. On the other hand, data is automatically surfaced from storage systems to applications, regardless of the APIs supported by the storage system. This concept extends beyond just API translation, functionality such as security rules and consistency guarantees are also abstracted from the storage layer and provided through Alluxio.
SparkSQL on Alluxio backed by S3
We ran TPC-DS 2.4 on SparkSQL backed by data in S3 to exemplify the benefits Alluxio brings to a decoupled compute-storage architecture. TPC-DS is the defacto industry standard benchmark for query-based big data analytics. The set of 99 queries were run sequentially, meaning earlier queries were cold reads while later queries benefited from Alluxio storage. The experiment was done on AWS with open source Alluxio 1.7.0 and Apache Spark 2.2. The cluster had four r4.4xlarge worker nodes each running an Alluxio worker and Spark worker.
The gray S3 data represents TPC-DS run against parquet data residing in S3, with Alluxio completely out of the picture. The blue Alluxio set represents the results when using Alluxio, but without any data in Alluxio to begin with. As the queries ran, Alluxio was hydrated with data and automatically managed its Alluxio storage based on the temperature of the data. For example, for frequently accessed files, multiple copies were stored in Alluxio to improve read throughput. We display the results of several queries which characterized different types of queries and the impact Alluxio had on them in the charts below.
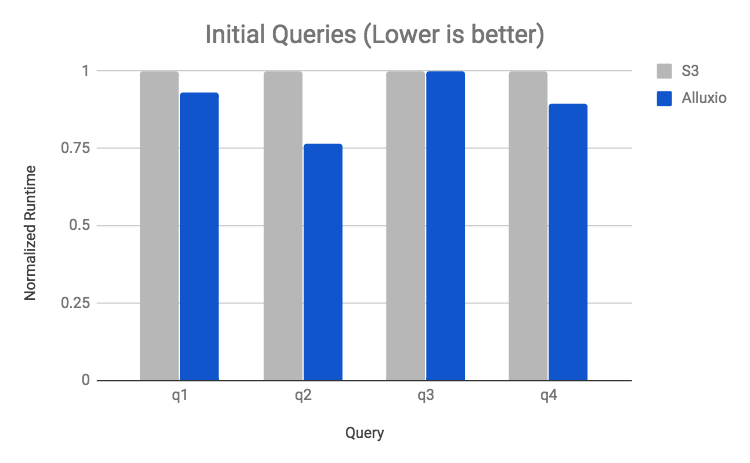
The first set of queries are the initial queries which access cold data from S3. These are almost identical to running without Alluxio because data must be fetched into Alluxio. From Alluxio Release 1.7.0 onward, the Alluxio worker intelligently and asynchronously fetches data in blocks based on client data access, so the hydration period does not impact the critical path and can even provide some benefits.
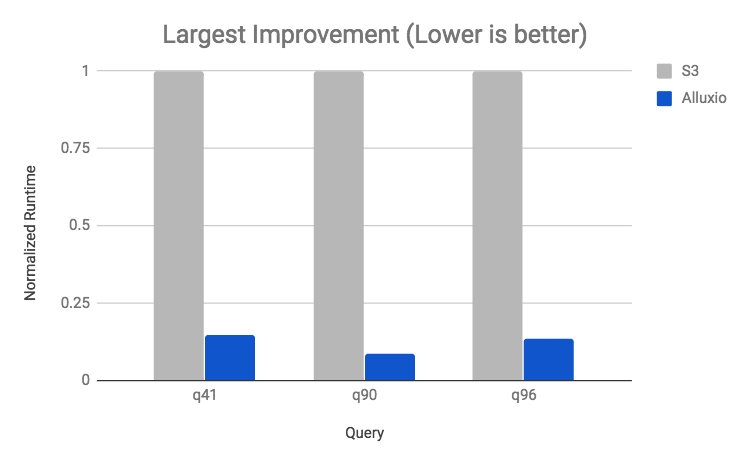
In the best case scenario, when most of the dataset is in Alluxio and the query is I/O heavy, Alluxio speeds up the query over ten times. Alluxio provides the most benefit for queries such as large scan operations. A big difference in using or not using Alluxio is having co-located memory-speed I/O versus network-speed I/O from S3. When evaluating a query, the longer the query is I/O bound, the more Alluxio can help with improving throughput. Since we used S3 and AWS, the network conditions were ideal and we could fully saturate the 10-gigabit link. For environments where the network or disk I/O has more contention or lower bandwidth, Alluxio will provide even greater performance improvements.
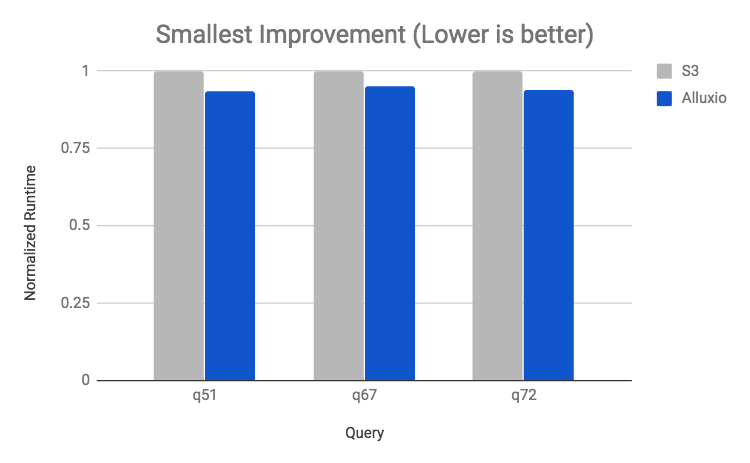
Conversely for queries which are extremely compute or shuffle intensive such as joins with complex predicates, Alluxio provides marginal benefit. For queries with both compute and I/O bottlenecked portions, Alluxio will accelerate the I/O bound portion, a middle ground between the most and least improved queries. There were no queries which performed worse with Alluxio in the stack.
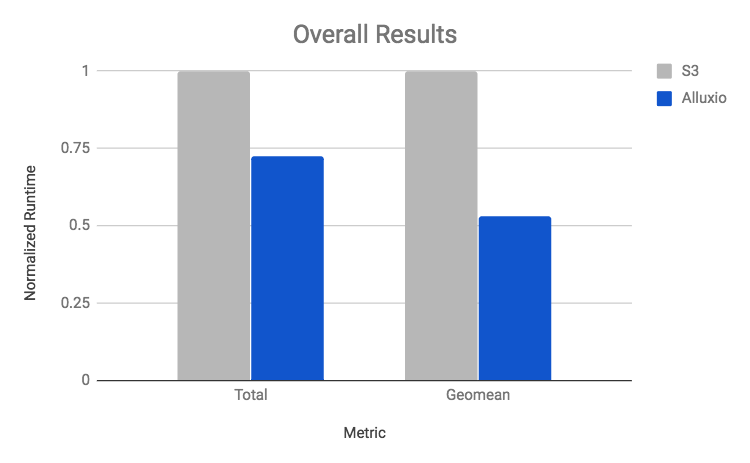
Comparing the total runtime, Alluxio is about 40% faster than directly reading from S3 even though Alluxio was not initially populated with the data. As the set of queries ran, Alluxio gradually was hydrated based on the data access pattern and frequency. However, total runtime does not tell the full story, since it is heavily weighted toward long running queries. Alluxio improves the geomean, which is derived if we weight each query equally, by almost 2x! These set of numbers shows that Alluxio provides benefits for all the queries represented by the TPC-DS workload and can improve certain queries by an order of magnitude. No queries are adversely affected by introducing Alluxio to the stack.
Conclusion
TPC-DS only represents one type of workload which benefits from Alluxio in a decouple compute-storage architecture. With Alluxio, applications requiring different APIs can seamlessly transition to accessing data from decoupled and previously incompatible storage without needing to deal with performance loss.