This post is guest authored by our friends at Arimo.
Deep learning algorithms have traditionally been used in specific applications, most notably, computer vision, machine translation, text mining, and fraud detection. Deep learning truly shines when the model is big and trained on large-scale datasets. Meanwhile, distributed computing platforms like Spark are designed to handle big data and have been used extensively. Therefore, by having deep learning available on Spark, the application of deep learning is much broader, and now businesses can fully take advantage of deep learning capabilities using their existing Spark infrastructure.
Distributed Deep Learning on Spark with Co-Processor on Alluxio
At the 2015 Strata + Hadoop World NYC, we presented the first ever scalable, distributed deep learning framework on Spark & Alluxio called the Co-Processor on Alluxio (“Co-Processor”) which includes implementations of feedforward neural networks, convolutional neural networks (CNNs), and recurrent neural networks (RNNs) (Check out the full Video and Presentation).
The Co-Processor adds computation to the Alluxio layer. In particular, it runs a custom process to monitor the derivatives directory and accumulate them. The idea is to use Alluxio not only as a common storage layer between Spark workers but also a model updater to support big model training. With its in-memory distributed execution model, the Co-Processor framework provides a scalable approach even when the model is too big to be handled on a single machine.
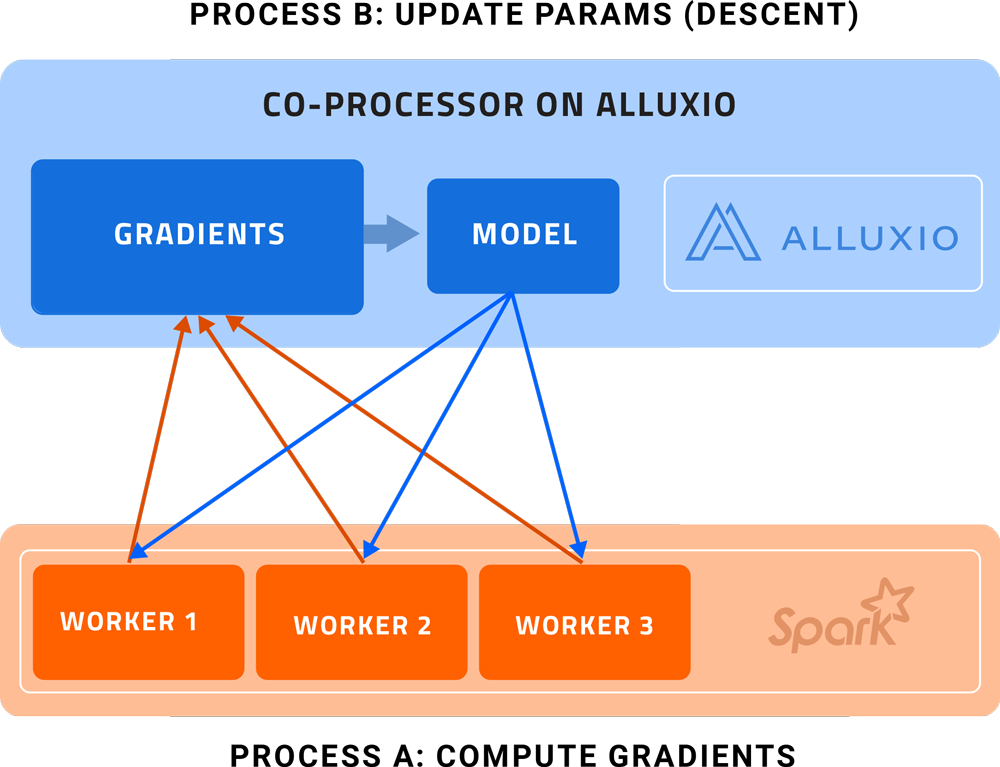
- Process A (Compute Gradients): Spark workers compute gradients and handle data-parallel partitions.
- Process B (Update Parameters): Alluxio applies the Descent operation and update the hosted model
Each Spark worker processes a portion of the training batch and computes the gradients and sends them back to the parameter server on Co-Processor. The parameter server not only gathers the gradients but also applies the descent operation as a co-processor and then update the model hosted in Alluxio (Process B). Note that process A and B occur essentially asynchronously.
This design allows us to avoid:
- Sending the aggregated gradients back to Spark workers
- Sending the updated model to the workers because Spark workers now have direct access to the updated model in Alluxio.
As a result, we are able to speed up the model training process to 60% by cutting down the communication cost between Spark workers and the parameter server significantly.
Ongoing Development
Popular open source deep learning frameworks like TensorFlow have their own architecture for distributed model training which normally involves a cluster of GPUs computing the gradients simultaneously for different portions of the training batches. Unfortunately these frameworks are still very limited in the ability to do ETL on large datasets.
One approach is to have Spark pre-process data for the TensorFlow server consumption. This, however, has its own flaws that could cause painful unproductivity.
Problem 1: Bottleneck in Training Data Generation
At Arimo, we work with large scale time-series data on a daily basis. Large datasets and complex learning problems usually require intensive, time-consuming ETL processing yet time-series data format is particularly challenging.
The modeling on this type of data requires (1) generating numerous sub-sequences and their associated labels through time and (2) reshaping the sub-sequences into multi-dimensional tensors.
The current modus operandi is to run a long Spark batch job to completely transform the raw data into the appropriate, Deep Learning-trainable forms. A long batch job is not optimal for our pipeline’s productivity, because we have to wait until all the data partitions have been processed before sending them to training. A more desired paradigm is to immediately stream the completed data partitions to the training phase.
Problem 2: Bottleneck in Training Data Transfer
To move the training data between Spark and TensorFlow, we normally need to persist the entire set of processed data to HDFS or any other distributed file system. Doing so, inevitably creates two disk IO bottlenecks in writing and data retrieving. This problem is severe when the training data is dozens of times larger than the original raw data, as is the case with time-series modeling.
Problem 3: Big Waste in Training Data
An interesting and important nuance: we actually don’t need 100% of the possible training data to train good models. This means the batch-job approach of generating the whole training data first and then using it is extremely wasteful. This insight is another key reason why we are moving away from the batch-job approach and towards a more efficient streaming one.
The solution: use Co-Processor to concurrently generate and stream training data mini-batches from Spark to TensorFlow
We can move data from Spark to TensorFlow servers much faster by avoiding disk IO and taking advantage of an in-memory shared file system like Alluxio. Let’s take a look at the diagram below:
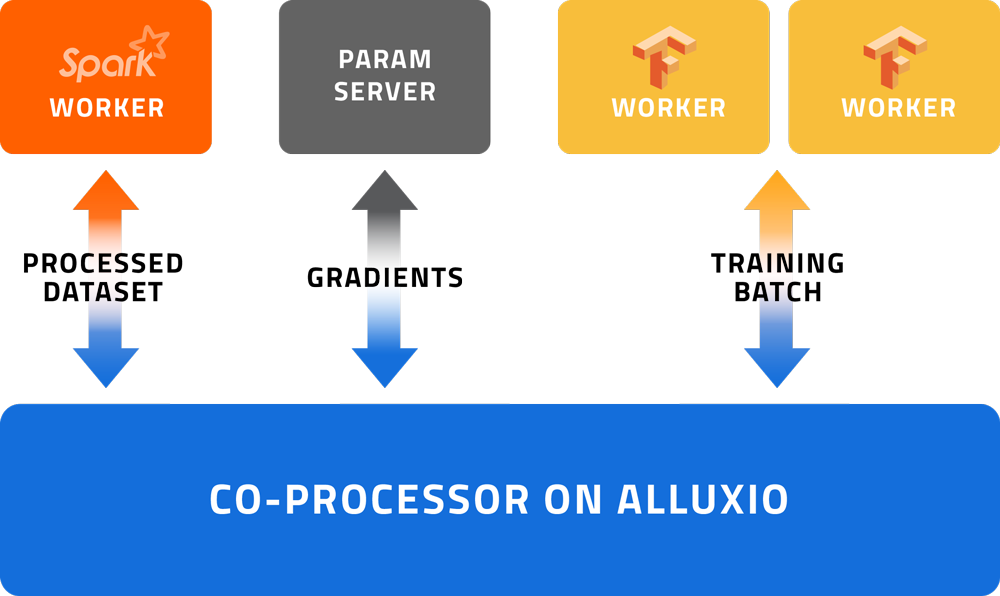
- With Co-Processing, the preparation of sub-sequences and labels starts immediately as soon as our data frames are created; so that while we are performing other unrelated operations, the training data is silently being produced and queued up, ready to be called up during the subsequent model training;
- Alluxio’s memory-speed storage alleviates our need to persist generated training data down to HDFS and suffer the resulting disk IO.
This approach is performant, elegant and very efficient. The waste is minimized—even eliminated with Co-Processor. We silently generate batches in the background, then consume the queued-up batches to train models only until the they are satisfactory. Data is constantly queued up and buffered between the generating and the feeding stages, and the compute-intensive data-preparation process ceases exactly when model training stops!
Streamlined and waste-less, the Alluxio-enabled approach is what we consider the “Toyota standard” for large-scale data preparation and model training.
Conclusion
Deep learning modeling works best when the model is big and trained on large-scale datasets. To speed up the model training process, we have implemented Alluxio as a common storage layer between Spark and Tensorflow.
We leverage Co-Processor’s memory-speed storage and co-processing capabilities to avoid disk IO bottleneck and implement concurrent tasks for training data preprocessing or hosted model update. The initial result was promising as it was able to speed up the model training process up to 60%.
We look forward to using Alluxio for other use cases & product integration.
About Arimo
Arimo, independently named one of the world’s top 10 most innovative companies in data science, offers the most innovative behavioral AI solution to help businesses increase revenues and lower costs. By operationalizing a new class of predictive models—that leverage behavioral data and other data sources to produce optimal predictions, Arimo Behavioral AI™ accelerates time to value for customers’ predictive use cases and increases data scientists’ productivity. Arimo’s customers include leading companies in retail, financial services and manufacturing.
Arimo is funded by Andreessen Horowitz, Lightspeed Ventures, and Bloomberg Beta.
To learn more, visit the Arimo website at https://arimo.com/