Processing and storing data in the cloud, such as Amazon S3, Microsoft Azure Blob Storage, or Google Cloud Storage is a growing trend. The global availability and cost effectiveness of these public cloud storage services make them the preferred storage for data. However, running data processing pipelines while sharing data via cloud storage can be expensive in terms of increased network traffic, and slower data sharing and job completion times. Recently, organizations have been deploying Alluxio to support various cloud-based pipelines, to improve performance and reduce costs.
Using Alluxio, data can be shared between pipeline stages at memory speed. By reading and writing data in Alluxio, the data can stay in memory for the next stage of the pipeline, and this can greatly increase the performance.
Alluxio Enterprise Edition (AEE) introduces Fast Durable Writes, a feature which enables low latency and fault-tolerant writes. In this article, we describe the Fast Durable Writes feature, and explore how Alluxio can be deployed and used with a data pipeline. We discuss the following:
- Fast Durable Writes in Alluxio Enterprise Edition
- Pipeline stages can share data with Alluxio memory for improved IO
- Applications of different frameworks can share data via memory with Alluxio
- Alluxio improves completion times
- Alluxio reduces performance variability
In this article, we use Alluxio Enterprise Edition (AEE) 1.6.0, Apache Spark Standalone 2.2.0, and Apache Hadoop MapReduce 2.7.2. The experiments were run using Amazon EC2 r4.2xlarge instances. The experiments used a 3-node cluster, where each of the nodes had a Hadoop NodeManager, Spark Worker, and Alluxio Worker.
Fast Durable Writes
Alluxio enables sharing data at memory speed with Fast Durable Writes (FDW). If stages in a pipeline share data via memory, the completion time of the entire pipeline is reduced. However, simply writing to memory is not fault tolerant; if a machine with in-memory data crashes, that data is not retrievable. Fast Durable Writes solve the issue by improving write performance, without sacrificing fault tolerance.
Fast Durable Writes (FDW) is an Alluxio write mode where the data is synchronously written to memory of multiple machines, and asynchronously written to the underlying persistent storage. For example, if Alluxio has mounted AWS S3 as an underlying storage, an FDW write will first write multiple replicas to memory (# of replicas is configurable per file). Once the replicas are written, the write is considered complete and the application can proceed.
Asynchronously, in the background, Alluxio will write the data out to S3, and eventually, the data will be in S3. This means the application does not need to wait for the write to complete to S3, which can lead to improved performance.

FDW improves write performance because writing to in-memory replicas can often be faster than writing to storage, especially remote cloud storage. While FDW writes to memory, it still provides fault tolerance because the data is on multiple machines, and if a machine crashes, that data can be re-replicated to another Alluxio worker. Once the asynchronous write to the underlying storage is complete, then the data is fully persisted on stable storage.
Example Pipeline
To explore how Alluxio enables sharing data between stages, we describe a simple log processing pipeline. This example pipeline has 4 separate stages. Since Alluxio works with various frameworks, we demonstrate that with the pipeline using different application frameworks for different stages. Here are the stages of the pipeline:
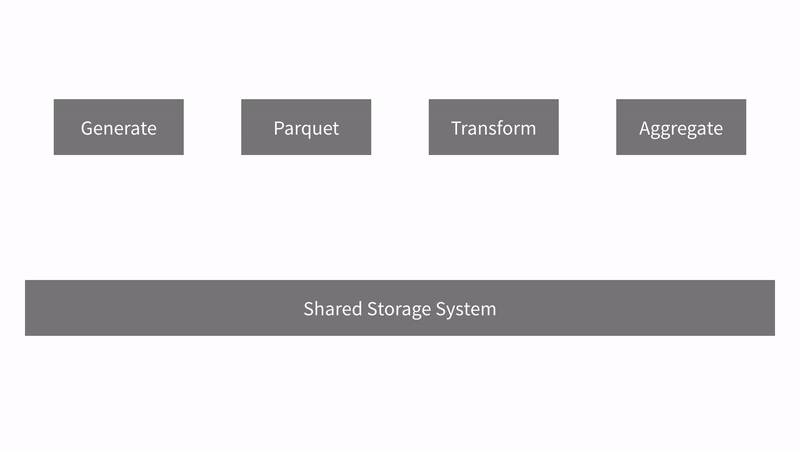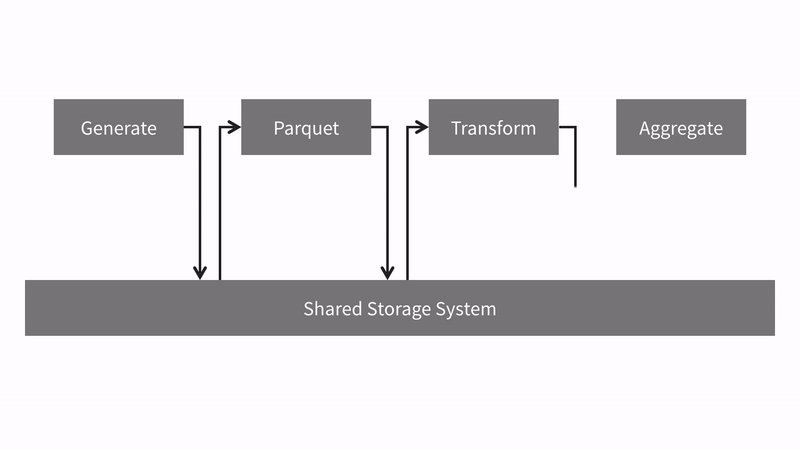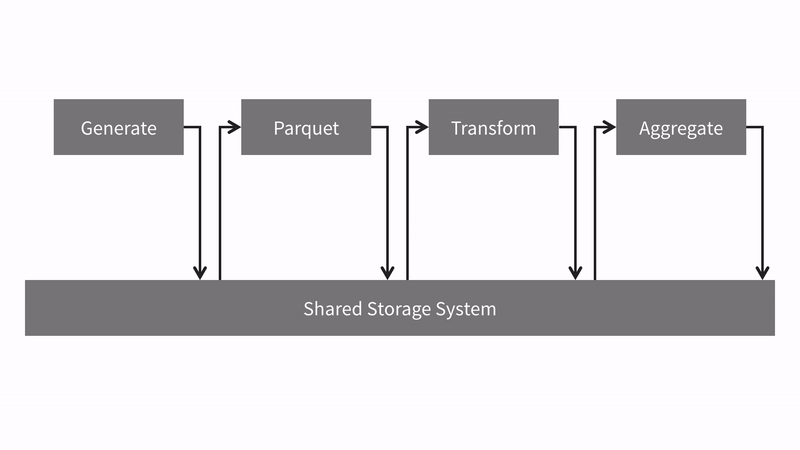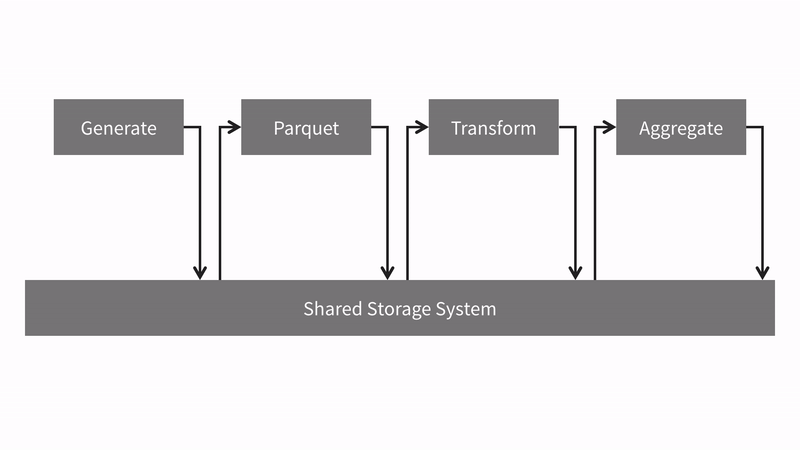
- Generate [MapReduce]. Create randomly generated CSV data.
- Parquet [MapReduce]. Read the CSV data and convert it to parquet file format.
- Transform [Spark]. Read the parquet files and transform column values.
- Aggregate [Spark]. Read the transformed parquet files and compute an aggregation.
For our experiments, the input data was randomly generated and was 12GB in total. Pipeline on S3 without Alluxio When pipelines are run in the cloud, like Amazon AWS, Microsoft Azure, or Google Compute Engine, the associated cloud storage options are typically used for storing data (S3, Azure Blob store, GCS). However, sharing data between stages in the pipeline via the object store may be costly in terms of performance and resources.
We ran the example pipeline 3 times with the data sharing via S3, and measured the completion time of each stage of the pipeline. The following table shows the completion times (in seconds) of the stages of each pipeline run.
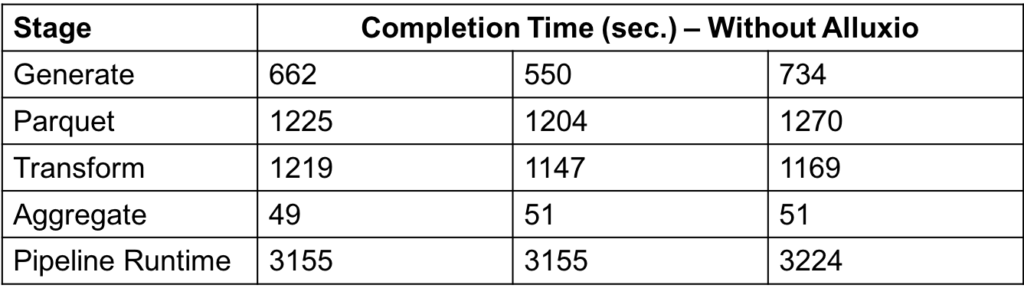
The average runtime of the pipeline is 3110 seconds. The experiments on S3 show that the pipeline on average takes almost an hour to process the 12GB of input data.
Pipeline on S3 with Alluxio
When pipeline data is shared across jobs using Alluxio, the data can be shared at memory speed. That has the potential to significantly speed up jobs. We ran the same example pipeline, but with the data being shared with Alluxio. We ran the pipeline three times and measured the completion time of each stage. The following table shows those completion times in seconds.
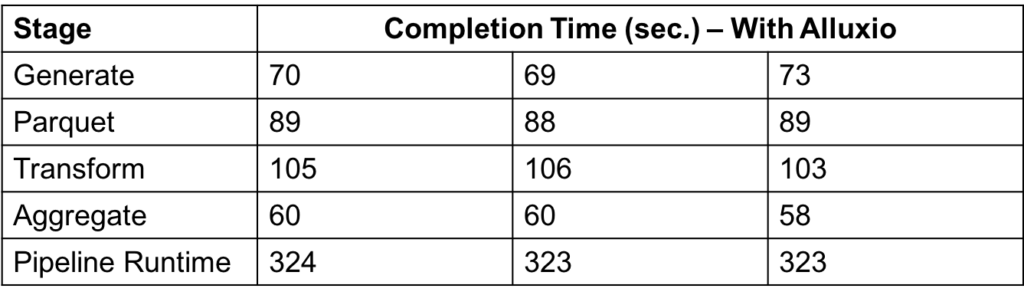
The average runtime of the pipeline with Alluxio is 323 seconds, over 9x faster than the baseline S3 run.
Below is a figure that shows the average completion time of each stage, for both the S3 pipeline and the Alluxio pipeline.
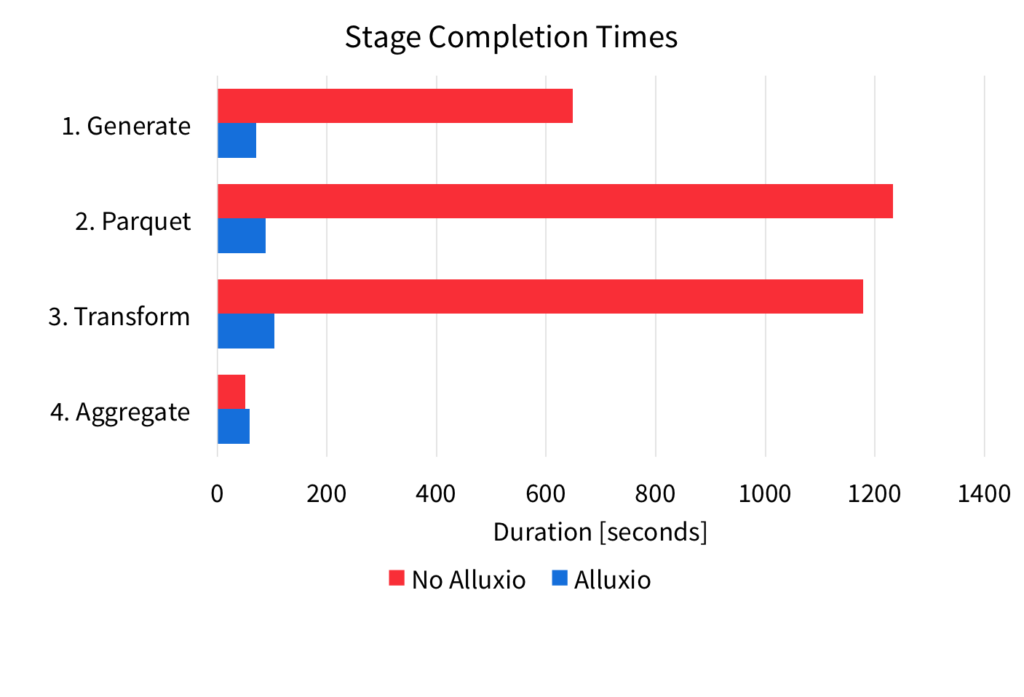
Since memory has lower latency and higher bandwidth, running the pipeline on Alluxio results in faster completion times for each stage of the pipeline. It is clear to see the faster performance that Alluxio and Fast Durable Writes enable.
For the entire pipeline, the following figure shows the average completion time over three runs of the pipeline, along with the min and max range (represented by the error bars).
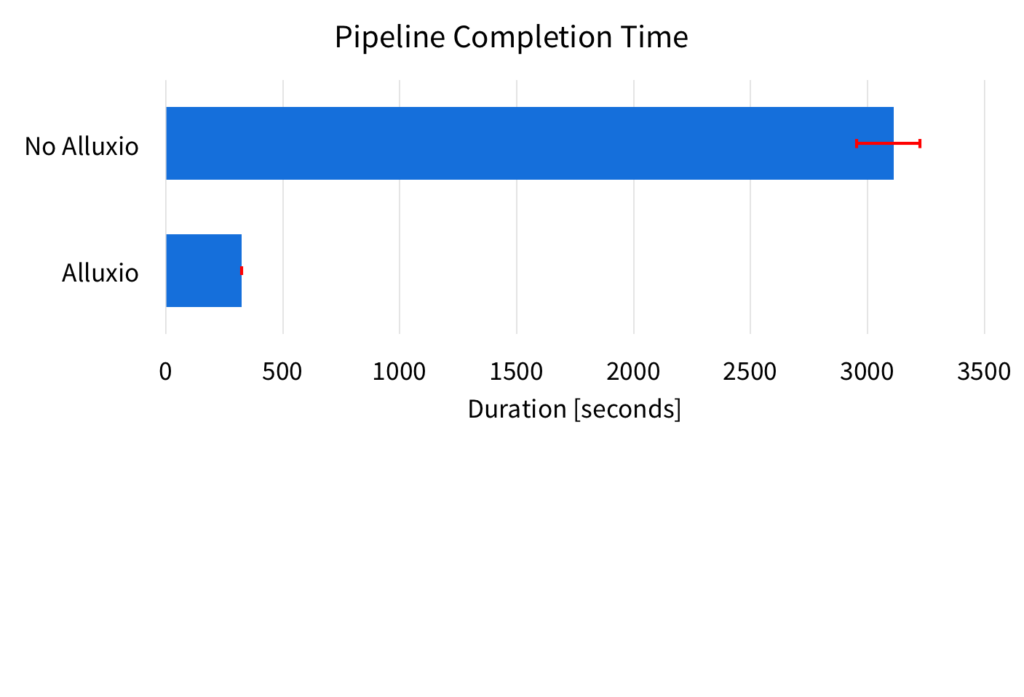
The result shows that Alluxio improves the performance of the pipeline, as well as the predictability of the completion times. These experiments show that the full pipeline with Alluxio takes about five minutes, over 9x faster than running on S3 without Alluxio. In addition, the min and max range of the completion time is greatly reduced with Alluxio. With Alluxio, pipeline completion time varies within one second, but without Alluxio, the completion times vary by more than four minutes.
These pipeline experiments show how Alluxio can be used to share data across jobs at memory speed. By using Alluxio to share data, the completion times of jobs is significantly reduced, and the pipeline completes in a more predictable manner.
Sharing Data Across Frameworks with Alluxio
Also, in our example, we are using applications from different frameworks, and Alluxio still enables memory speed data sharing across different applications and different frameworks. Since Alluxio exposes a filesystem interface, applications from different frameworks can still share data via Alluxio memory. By storing data as files in Alluxio, other jobs (from other frameworks) can read the files from Alluxio memory, thus increasing the IO performance.
In the example pipeline of this article, two different frameworks were used for the stages of the pipeline: MapReduce and Spark. This highlights that even when different applications and jobs are of different compute frameworks, they can all use Alluxio as the storage platform to share data in memory, and realize the benefits of Alluxio.
Conclusion
Alluxio, and Fast Durable Writes, enables sharing data across applications at memory speed. This blog shows that for a simple pipeline of several stages, sharing data with Alluxio results in several benefits:
- Fast Durable Writes improves write performance, without sacrificing fault tolerance
- Pipeline stages can share data with Alluxio memory for improved IO performance
- Applications of different frameworks can share data via memory with Alluxio
- Alluxio improves completion times
- Alluxio reduces performance variability